Serialization Throughput
Ward Cunningham
Cunningham & Cunningham, Inc.
December 30, 2001
Klaus Wuestefeld suggests replacing conventional
database with in-memory storage.
See www.prevayler.org or the
related advogato article.
He depends on logging serialized objects and is thus concerned with the throughput
of java serialization and related i/o on a variety of platforms.
The java benchmark offered on advogato repeatedly serializes a single Integer and
computes a single Integers-per-second metric.
I have generalized Wuestefeld's benchmark to serialize
various size arrays. This provides a better characterization of
likely logging performance for realistically sized objects.
Here is the java source
and corresponding class file.
This program writes tab-separated output suitable for further processing
with a spreadsheet program.
I've run this program on several pc-class machines and
collected the following results. Click on the images to see the full size graphs.
|
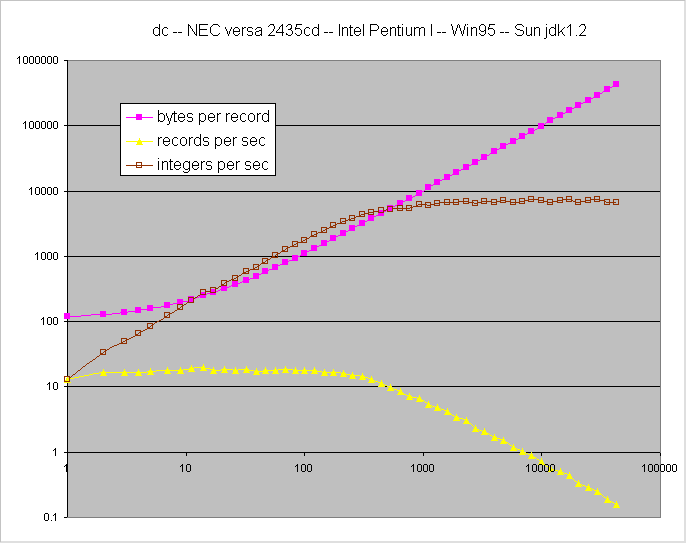
raw data
This is the oldest computer I tried, and apparently the simplest.
It is the only one to exhibit the expected behavior.
The writing rate for small records (less than 300 Integers) is dominated
by fixed overhead so that the number of records per second is constant.
Conversely, transfer time dominates writing of large records so Integers per
second becomes constant.
|
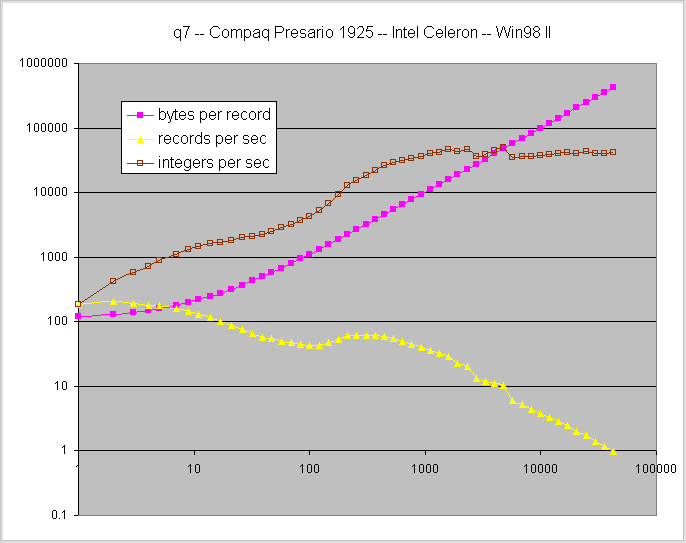
raw data
Here the boundary between small and large records is more confused. Presumably newer
software is adapting to i/o traffic and trying to optimize somehow. I could hear the
disk drive seek while this data was collected. The seek rate varied throughout the run
with the highest seek rates correlated with poorer performance numbers. I developed
my modifications on this machine. Every one of dozens of runs showed similar characteristics.
|
|
I also ran the benchmark on a couple of linux servers. I used the koffe jit interpreter
that comes with Red Hat 6. I can't explain the sudden drop in performance that occurs
with the largest records. I repeated these runs several times and got nearly identical results.
|
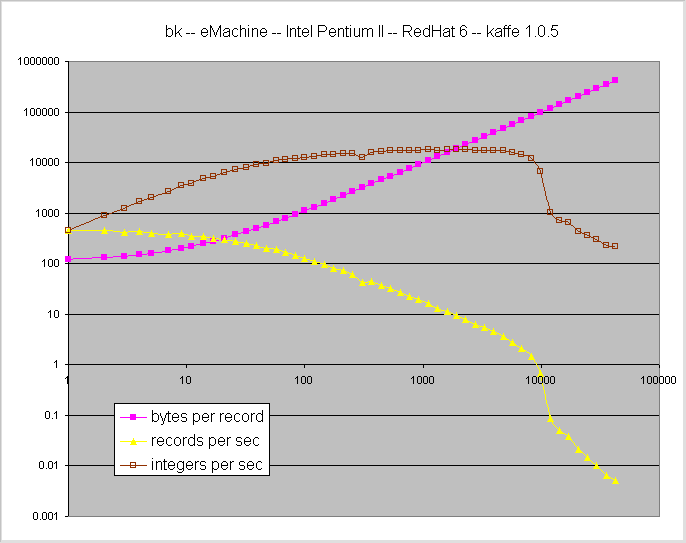
raw data
This is an unloaded server except that I had a couple of telnet connections open
and did poke around a bit as the benchmark ran. This may account for the slight dip
at one data point. A second run had a similar dip, but at a smaller record length.
|
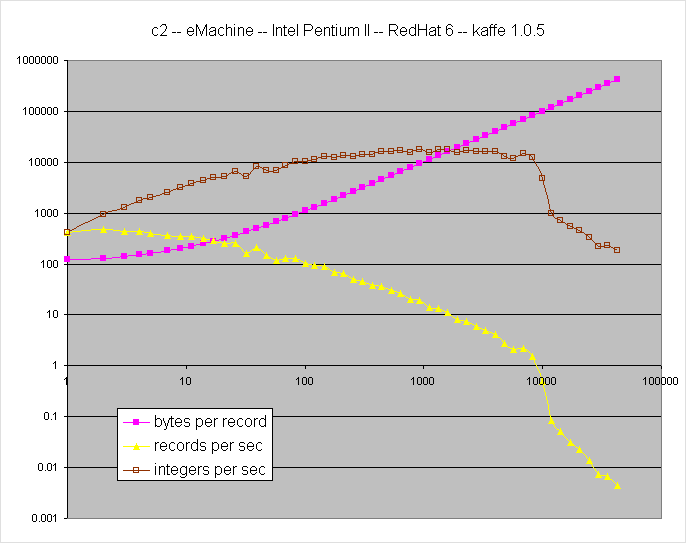
raw data
This is a nearly identical sever except that it hosts the c2.com web site
which serves a continuous load 24 hours a day. Note the very similar behavior
as the other server except for a slightly higher variation in individual measurements
which I attribute to web server activity. |
|
I'd be happy to post more performance curves here if they vary significantly from
these that I have already collected. Send a zip with your raw data and a brief description
of your configuration to ward@c2.com. Include your machine
name, processor, os, and vm.
I wouldn't expect my modest computers to be exceptionally good database machines. However,
all achieved performance on the order of 10,000 Integers per second for realistically sized
objects. This is much more comforting than the numbers in the small hundreds that Wuestefeld has
reported for his first order benchmarks.
|
|
Nick Lothian nl@essential.com.au writes ...
I've run the SerializationThroughput benchmark on my machine (Pentium 3/700
with an IDE Hard Drive) under Windows 2000. You'll notice they are fairly similar - the
Sun VM handles large object slightly better, but they are close with smaller
objects.
You can observe some strange behaviour of records per second at small object
sizes (eg, record sizes 7,9,11,14 in both files). If it weren't for the fact
that both VMs behaviour similarly at the same record sizes I would have
thought it was an artifact of some kind. I couldn't think of a reasonable
explaination for this behaviour.
|
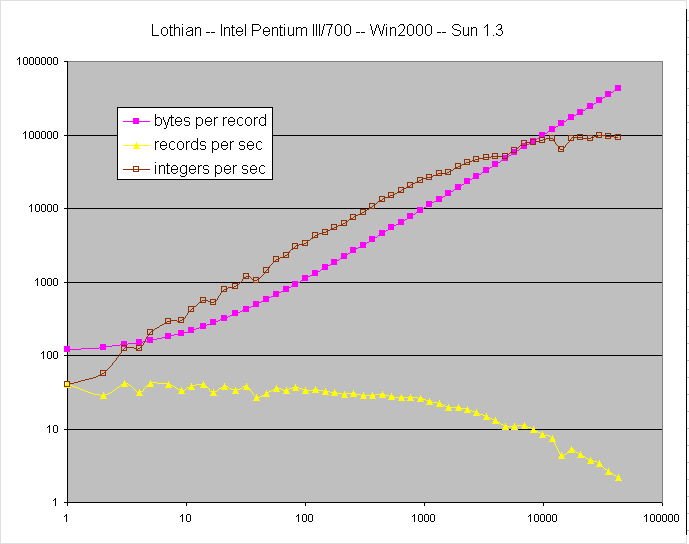
raw data
Sun JVM 1.3 ( Java(TM) 2 Runtime
Environment, Standard Edition (build 1.3.1-b24), Java HotSpot(TM) Client VM
(build 1.3.1-b24, mixed mode) ). |
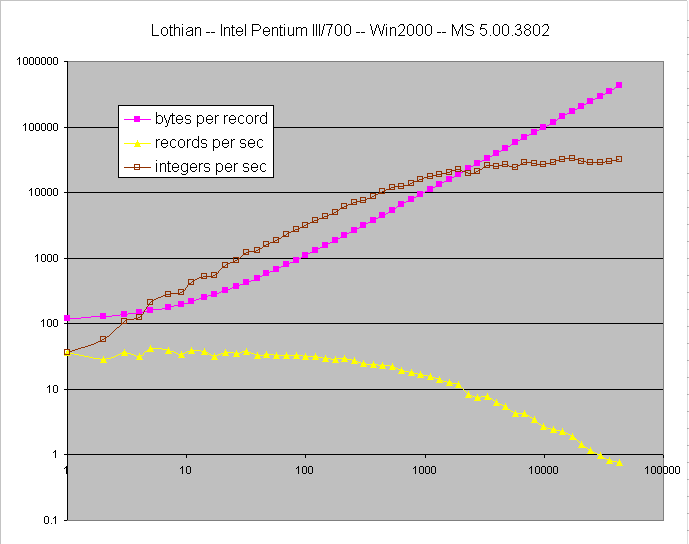
raw data
MS virtual machine ( Microsoft (R) Command-line Loader
for Java Version 5.00.3802 ) |
|
Others have been kind enough to send me their results too. I've pooled their and
this data here and ploted it all to the same scale.
© 2001
All rights reserved.
|