For years organizations have deployed and used large on-line transaction processing(OLTP) systems to automate and record their business activity. The challenge now is to allow business analysts, those individuals in the organization chartered to support decision makers by producing reports, to access this data in an ad hoc manner. While OLTP schema are optimized for data entry, they seldom provide an acceptable solution for data analysis.
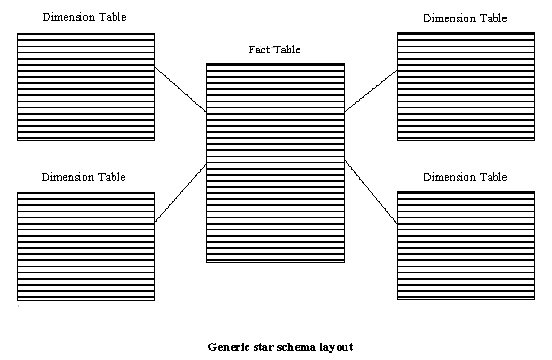
The star schema concept presented here is the product of many discussions over the years between the author and consultants specializing in Decision Support Systems(DSS). The star schema has also been called a star-join schema, data cube, data list, grid file, and multidimensional schema by practitioners in the field. The name star schema comes from the pattern formed by the entities and relationships when represented as an entity-relationship diagram(ERD); Typically there is a business activity in the center of the star surrounded by the people, places, and things that come together to perform this activity. These people, places, and things can be thought of as the points of the star.
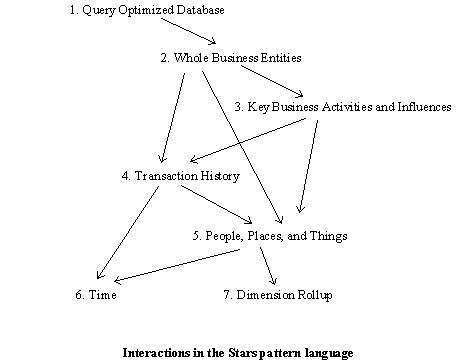
The star schema pattern language presented here is an attempt to provide a method for business anaylsts to develop a schema which is easy to query. Seven patterns are presented which are part of a larger pattern language that support the field of DSS, a branch of Business Data Processing Systems. The seven patterns are split into two sections. The first section addresses the issue of finding and organizing the relevant factors of the business that need to be analyzed. The second section deals with implementing these factors into a star schema for a query system.
Analysis Section. To begin, make a list of those things that are meaningful to your situation as you try to discover the entities that model that part of the business for which you are responsible. Your model should contain the names of things that are readily recognized by anyone working in your area. As the model is refined, it should reflect those activities and the things involved in those activities that are directly relevant to trends that your business is influenced by and can influence. The patterns are:
1. Query Optimized Database
2. Whole Business Entities
3. Key Business Activities and Influences
In the ongoing operation of your business area, be it Sales, Marketing, Manufacturing, Engineering, or whatever, the need arises to analyze your business in order to solve a problem. These problems could be something like the need to correct poor performance or seek new opportunities. Solutions and opportunities are usually found by analyzing the data that is captured as a part of the ongoing activities of the business. This data is usually found in your company's OLTP database(s).
OLTP database schema are usually optimized for the recording of business transactions. The normalization process for OLTP schema design takes descriptions of entities from the business domain and breaks them apart into a number of small tables. These small tables can then be handled by the DBMS in an efficient manner. Breaking up entities into small tables also reduces the amount of redundant data stored in the database since these each table can be joined with other tables to form more than one business entity. Reducing data redundancy means that the same piece of data will only be stored in the database once. By having the data stored only once, the problem of updating multiple copies disappears when the data changes.
Two problems arise when a you want to query an OLTP schema. First, the fields that describe one of your business entities will be distributed among a number of tables which will then need to be joined together in order to form the things that you will want to use in your analysis. These joins that have to be performed can each require a significant amount of processing by the database system. Second, since these small OLTP tables have to be joined back together to form the original entity, there will usually be multiple combinations of joins from which to choose. These multiple ways of joining tables can lead to varying answers when the tables are used in a query. Even if different combinations of joins happen to yield the same answer, the join process can be error prone to a person who is not knowledgeable about the details of the schema. Therefore:
Develop a new database optimized for the purpose of easy query rather than for inserting and updating data. The new database will most likely have to be implemented on a separate machine from the one that hosts the OLTP database since long queries could adversely affect the performance of the data entry process if the two databases are run on the same machine. Besides the performance issue, another reason to separate the two types of databases is that the DSS database will need to have stable data in order to perform meaningful analysis. If the DSS is implemented as views on an OLTP database, the data within the views will be constantly changing as the data entry process captures new and updates old data. The problem with trying to do analysis on constantly changing data is that you cannot hold some of your variables constant while selectively changing one or two other variables, in order to see the effects of these variations on your results. This is called the Twinkling Data Problem.
The new database and machine will incur additional costs for ongoing administration and maintenance. The issue of transferring data between the OLTP and DSS databases will also need to be addressed as the DSS database will need to be refreshed with new data on a periodic basis. Having data from the OLTP system appear on reports generated by the DSS will bring to light the errors that occur during the data capture process. These errors will need to be corrected in the OLTP database by either scanning and cleaning up the data before each transfer to the DSS or, better yet, refining the data capture process to include ways of catching and reducing errors at the time data is entered.
The rest of this pattern language is concerned with finding the entities that you need to model for building a schema which is easy to use. Form Whole Business Entities(2) from your OLTP database that are relevant to your domain. Grouping together all of the relevant data for a given entity will reduce the number of joins in a query. In essence, you will denormalize the OLTP schema to a degree which will allow for faster query. This shouldn't present a problem in the DSS database since it should only be updated on a periodic basis, usually in a batch mode of processing. Using batch processing, the updates to the DSS database can be controlled since they are only coming from one source. This is a much more managable scenario than with an OLTP database where updates are coming from multiple sources in an ad hoc fashion.
Once you have a list of reconstituted entities that model your business area, use Key Business Activities and Influences(3) to focus on those events that are critical to your area of responsibility and the factors which influence them. Its important to make the relationships between the activities and their influencers simple and clear so that forming queries will be easy and accurate. By simple and clear I mean that there is only one join possible between any two tables and the meaning of that join is clear to the person performing the query.
The schema will be developed by defining and implementing two kinds of tables. The first kind of table, called a fact table, will be a Transaction History(4) of the key business activity being modeled. The second kind of table, called a dimension table, will be the People, Places, and Things(5) that are involved in each kind of transaction. Another dimension table, Time(6), is considered separately since it appears frequently in business analysis and deserves special attention. Dimension Rollup(7) is another kind of dimension table which help the person querying the database to specify groups of dimension records
In order to understand a schema that is developed for your business, you will need to use easily recognized names for the objects in your Query Optimized Database(1). Names for the objects in your schema should reflect those things in your environment that you deal with in your day to day endeavors. Each object should be whole in the sense that all of the things that uniquely describe it should be found in one place.
The business entities that you find on the reports of your business activities are usually scattered into a number of small tables in the OLTP database because of the need for normalization. The names for these small tables are usually concatenations of abbreviations for the business functions in which they participate. Your job in this case is that of solving a jigsaw puzzle whenever you want to form a query. Unfortunately for you the same piece can be used in more than one place and you only get one copy. Typically you'll need to ask for help from someone intimately familiar with the details of the OLTP schema. This can be a formidable bottleneck to getting timely answers to your business questions. Therefore:
Find the entities in your domain that are directly relevant to your problem by examining the reports you use to monitor your business. The report titles and column headings are the best places to focus on. As you find these entities, make a list of them. Put a short definition next to each entry. Another place for finding entities is from entity-relationship(ER) diagrams of the original analysis done for the OLTP database before it was normalized. The database administrator(DBA) for your OLTP database may have these diagrams available.
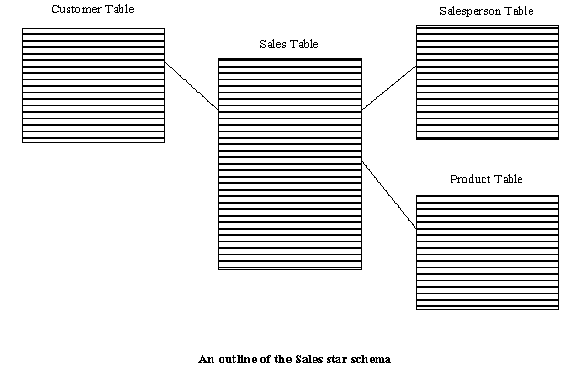
Example: List of entities in a sales model Customer - the people and companies we sell to Product - the things we sell Sales - a transaction between our company and a customer Sales planning - setting sales goals and procedures for the coming period Sales plan - a statement of goals for sales and the steps to achieve those goals Date of sale - the date of a sales transaction Distribution Channel - the means by which the product was sold to the customer Salesperson - the person who sold the product to the customer Competitor - the other companies who offer competing products Sales Office - a location where a group of salespeople are managed
The entities you find here will need to be made whole again from the pieces found in the OLTP database. The fact tables and dimension tables will be where you group together the information for each entity. At this point though, not all of the entries in your list will become tables. You will need to hone in on the things that are important to you by finding the Key Business Activities and Influences(3) that you need to analyze. At this point, don't worry that you have included too many entities; Its more important to brainstorm and find as many as you can. Entities that may seem superfluous at first may lead you to find other useful ones.
The things that you find in your business all have a role in the processes that produce your product. Finding the role of each thing is as important as finding the thing itself. Starting with Whole Business Entities(2), you will characterize these objects according to how they are related to one another. By defining these relationships you are also defining the role of each thing. The two categories of things that you will be concerned with will be the activities for which your department is responsibile and the various factors which influence them.
Tables in an OLTP database can have circular references. This usually occurs because normalized tables participate in a number of relationships since the data in the table is being reused. This reuse occurs to reduce data redundantcy. What this means is that I can start specifying the joins between some number of tables that circularly refer to one another in more than one way. This can lead to problems as the order in which I join the tables in one query can yield an answer that is different from a query using the same tables joined in another order. Depeding on the question I'm trying to answer, each join may give an answer that might be right or wrong. Without knowing the meaning of each join beforehand, I can't reliably form a query that will give me the answer I expect. Unfortunately neither the database nor the query language can help me with validating the joins against my intentions since the meaning of the relationships between tables isn't stored anywhere. Therefore:
Determine the key business activities in your domain and find the people, places, and things(dimensions) that play some part in one or more of the activities. People, places, and things will be found in the transactions that are recorded for your key business activities. Each transaction will usually describe who, what, when, and where the event took place. These are the simple relationships you need to define between each dimension and its activity. Be careful that the dimensions that you choose should only be related to each other through the key business activity and not with each other. There should be no direct relationships between dimensions except in the case of a Dimension Rollup(7).
In all cases, circular relationships should not be found between the dimensions, the facts, or any combination. It is important to draw out these relationships and make them clear so that you will be able to see the effect that any one of these dimensions has on your business activity. Your job as an analyst will be to see how a change in the value of one of these dimensions influences your key business activities. Starting from the opposite end, once you spot a trend in a business activity you'll want to identify the changes in value of your dimensions to find correlations between the activity and dimensions. Choose the key business activities for your area of responsibility from Whole Business Entities(2). The short definitions will help you spot these. Although these activities should already be found on your list, you may need to look deeper into your business environment to come up with all of the activities you'll need to consider. Limit the activities to only those that are directly related to the mission of your department. Some of the activities on your list may be supporting processes for main activities. Focus on the main activities since these will be critical to your businesses survival and growth. Each key business activity will become a fact table to hold Transaction History(4) in the query optimized database you will build.
For each of the main activities that you identify, make a list of the people, places, and things that are related to this activity. Again, you will probably find these from Whole Business Entities(2), but some may not be present and will only be found through further analysis of your business. Also, be sure to look at the short definition for each item in the list as this will usually have descriptive words which will give important clues for finding these things. Each of the People, Places, and Things(5) will become a dimension table in the query optimized database. The following example assumes that Sales is the key business activity that you should focus on from the example list in Whole Business Entities(2).
Example: List of people, places, and things that are involved in Sales Customer Product Salesperson
Implementation Section. In order to start analyzing your business model, each entity needs to be represented in your query system. Each entity should take the form of a table or the field of a table, as is appropriate for your particular query system. Each table should be complete in that when a report is created, all of the fields that either need to appear on the report or will be needed to specify the report should be available. Tables will represent the following:
4. Transaction History
5. People, Places, and Things
6. Time
7. Dimension Rollup
Some activities will be critical to the life of your business. These activities, along with the factors that influence them, are your Key Business Activities and Influences(3). For an activity, it will be convenient to have one place where you can start to refer to all of its dimensions. Here is where you need to build a fact table to contain these references. This will be the center of your star. In addition, the transactions that represent an activity should capture the units of work that are the basis for measuring your business' output. These are the facts about the transaction.
In an OLTP schema, the facts that represent your key business activities, and their dimensions, may be scattered throughout the database because of the normaliztion process. Chains of tables may have to be joined together in order to find all relevant facts and dimensions. This chain may include tables that are irrelevant to your business question but may be needed simply because they contain the references to other tables that you need in your query. This can be wasteful in terms of performing expensive join processing when producing your Whole Business Entities(2). In addition, the join process itself can be error prone as discussed in Key Business Activities and Influences(3). Therefore:

Construct a fact table that contains the transaction history associated with each activity being modeled. The fact table should have an ID field for each dimension represented as People, Places, and Things(5) related to the transaction. Also put the numeric data, or facts, that are unique to the transaction in the fact table. The fact table is the agent that binds together all of the pertinent facts and dimensions for a transaction. It describes the who, what, when, and where by pointing to the dimension tables and it also contains the amounts of the things that changed hands between the parties of the transaction. Note that its important at this point to confirm with a person knowledgeable in the details of the OLTP schema, typically the DBA, that the data needed to build the fact and dimension tables exists in the corporate database(s).
The facts are usually numeric quantities that describe how much product has been sold and the money received for the product. This numeric data can be summed when a group of fact records are selected. This sum would represent the total activity for some set of criteria specified in the query. Data that is descriptive in nature, like textual names and enumerated type codes, should be placed in the appropriate dimension table.
Sometimes there will be descriptive data that isn't related to any of the dimensions and yet is associated with the transaction. This hard to place data will usually be put in the fact table when there are not enough fields to form another dimension table. In some instances your facts won't be numeric values but instead will consist of only coded fields which capture one of a predefined set of values. In programming terms this would be a field containing an enumerated type. For instance, your fact table would contain mostly enumerated types if you were storing the results of an opinion poll.
The IDs can be thought of being used in two ways. An ID in the fact table can be used to retrieve descriptive information from the dimension table. This is useful when you want to specify on a report the who, what, where or when of a transaction. Another use of an ID field is to find out what has taken place for a combination of people, places, or things. This is accomplished by taking the ID values from each of dimension tables and matching each combination against those stored in the records of the fact table.
The relationship between the records in a dimension table to the records in the fact table will be one-to- many; One record from the dimension table can be related to many records in the fact table. The opposite will usually not be true since you will want to identify only a single person, place, or thing involved in a transaction most time to simplify your analysis. In the case of Time as a dimension, a transaction usually only occurs at one particular time.
When transferring data from your OLTP databases to your query optimized database(DSS), you will need to keep in mind that you will probably be aggregating data from the OLTP databases. The OLTP database will have data that is captured at the time that the transaction occurs. If the transactions occur daily, then the OLTP data will be stored as of the day the transaction occurred. If your timeframe(Time(6)) for storing data in the query optimized database covers a longer period, then you will need to aggregate the OLTP data while you are making your periodic batch transfers.
Here's an example of the need for aggregation. If you were storing monthly transaction records for sales in your DSS, and you've determined that the dimensions for sales are customer, salesperson, and product, then you will need to aggregate the daily OLTP records into a monthly record for each combination of customer, salesperson, and product that made a transaction. The total number of records possibly created for this fact table would be calculated by multiplying the total number of records for each of the time unit(month), customer, salesperson, and product dimensions together; 12 months X 10 customers X 20 salespeople X 5 products = 12,000 possible records. Since not all of the possible combinations will typically be true for your business in every month, there would only be a fraction of that number of records created.
An important part of analyzing your business will be in detecting trends in Key Business Activities and Influences(3). In order to understand the cause of a trend, you will have to look at the different dimensions of the activity and discover correlations between the data values in the dimension tables and the fact table. Here is where you will create those dimension tables that describe the people, places, and things that each record in the fact table will reference. The dimension tables are the points of the star.
In an OLTP schema, the information describing a dimension is usually scattered throughout some number of tables. This can make the generation of reports a challenge as the information needed for the report must be constructed from joining together those tables that contain the fields needed. Besides the complexity of properly determining the joins, the process of joining itself is computationally expensive. Without the capability of being able to easily query your data in an ad hoc manner with reasonable response time, the process of analyzing your business data may be prohibitive. Therefore:
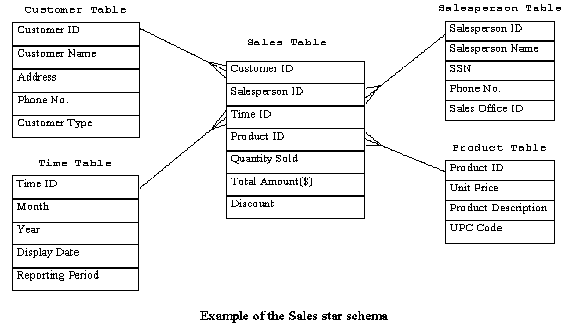
Develop a table for each person, place, or thing that has a part in the transactions that you are examining. These Dimension tables should model a person, place, or thing completely in so far as to contain all of the fields you need for your queries. You will find these dimensions among your Whole Business Entities(2). The fields will hold quantitative and qualitative values that will be used for displaying information on reports as well as being used for filtering records for calculations. Consider Time(6) as another dimension. Refer to the Sales star schema to see examples of dimension tables.
Since each record in a dimension table will represent a real thing in your business you should have an ID field that contains a value which uniquely identifies each record. The ID field will be used in the fact table as well so that records between the two tables can be joined. Therefore thinking about querying a database with a star schema entails starting from the points of the star, the dimension tables, and specifying criteria for each dimension table which will select some set of records from the center of the star, the fact table. Following is an example which uses the Sales star schema example shown previously.
SELECT c.Customer_ID, Customer_Name, Address, sum(Quantity_Sold) FROM Sales s, Time t, Product p, Customer c WHERE Month = 3 AND Year = 1993 AND UPC_Code = 12678754390 -- Gum Balls AND s.Time_ID = t.Time_ID AND s.Customer_ID = c.Customer_ID AND s.Product_ID = p.Product_ID GROUP BY c.Customer_ID ORDER BY c.Customer_ID;
This example finds the name and address of each customer who bought gum balls along with the total quantity purchased in the month of March 1993 using SQL syntax. Implicit in the example is the fact that all of the dimensions are related to each other only through the sales fact table. Thus forming queries using this type of schema consists of having a set of simple one-way joins, from each dimension to the fact table. Since no circular joins between tables are possible, at least if you designed your schema correctly, there is no ambiguity of where to start queries. Only in the cases where you have a Dimension Rollup(7) will there be a need to directly relate the dimension tables to one another without relating both dimension tables to the fact table first.
In general when you are analyzing a trend in one of your fact tables, start your query by specifying values for some of your dimension tables, in other words constraining them, and look for correlations in the data values between the uncontrained dimensions and the fact table. For example, if you wanted to find out why a particular product wasn't selling well in a given sales office, you could start by holding the product and time constant and list the types of distribution channels available for all sales offices. It could turn out that the distribution channel mix in the poorly performing sales office is significantly different than in the others, giving you a starting point for further investigation. This process of investigation is called "drilling down" into the data.
In order to measure the changes in your business' activity, data has to be analyzed from one particular time to another. These changes may show a trend over a series of subsequent time periods. The trends will be places where you will want to look for causal relationships between your activities and their dimensions.
There is usually no inherent time period that the transactions in an OLTP database are grouped by since all that is needed is a running log of activity from which to guide a continuous process. On the other hand, when you're analyzing one of your business activities, its best to have groups of transactions in order to get a "feel" for what's going on without getting bogged down in the details. Another problem you will encounter when analyzing OLTP data is that time can vary between transactions since they are entered in an ad hoc manner. Yet, the units of time you chose to group transactions should be uniform so that direct comparisons can be made between time periods. These uniform units of time should also not be chosen arbitrarily but should be meaningful to your analysis. Therefore:
Build a dimension table that will contain units of time that correspond to some significant event in your business. These significant events will usually be the reporting periods when management expects a summary of the business' activity. The unit of time chosen will determine the level at which your transaction data will be aggregated in your Transaction History(4). For example, if you chose your unit of time to be a month, since reports are made to upper management monthly, then daily transactions from the OLTP database will need to be aggregated into monthly transactions. For efficiency, when the data is loaded into your fact table it should be ordered by month so that it doesn't have to be sorted for each query.
There will be times when you'll want to "roll up", or aggregate, the level of activity in your business so that you can see the "big picture" for some group of records found in one of your dimension tables. This higher level of aggregation is a convenient technique used in a query. The convenience comes from only having to specify one record in the rollup table to represent many records in the associated dimension table.
The Transaction History(4) will already have been modeled with some level of aggregation assumed. These assumptions for aggregation are based on some intuition about how the data will normally be used. For instance, if you are mainly concerned with tracking the performance of individual salespeople, your fact table will be defined for transactions that reflect the sales of individual salespeople. If the requirement arises that you will need to analyze sales performance on the basis of a geographic area, like a sales office, then all of the sales for the salespeople that are a part of that sales office will need to be analyzed together. Specifying each salesperson that is part of a sales office in a query can be laborious. Alternatively, designating a field of the salesperson table to contain a coded value signifying a particular sales office may be inadequate since there may be other information about the sales office which will need to appear on a report. Therefore:
Design a table for the new entity that represents the larger organization that will encompass your existing business dimension. As with People, Places, and Things(5), this new table should include all of the information related to the thing that you will need for including on a report or using as filtering-criteria in a query. You may find that these kinds of things are already in a list of your Whole Business Entities(2).
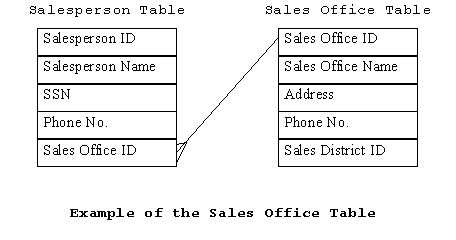
Like all dimension tables found in People, Places, and Things(5), the table should have an ID field which will uniquely identify each record. This ID field will also be found in the dimension table for which it is aggregating. By having the two tables related by a common ID field, you will be able to easily specify a groups of records in the lower level dimension table by specifying the appropriate value for the ID field in the dimension rollup table. Each of these lower level dimension records will in turn be related to their associated records in the fact table, since these too are related by a common ID field. The fact records can then be summed to yield a quantity that relates back to the rollup dimension. Note that rollup dimensions can be nested to an arbitrary depth to reflect your business. An example of using the Sales Office table to find out the total dollar amount of gum balls that the Portland sales office sold in the month of March 1993 using SQL syntax would be:
SELECT Sales_Office_Name, Product_Description, sum(Total_Amount) FROM Sales s, Time t, Product p, Salesperson sp, Sales_Office so WHERE Month = 3 AND Year = 1993 AND UPC_Code = 12678754390 -- Gum Balls AND Sales_Office_Name = 'Portland' AND s.Time_ID = t.Time_ID AND s.Salesperson_ID = sp.Salesperson_ID AND sp.Sales_Office_ID = so.Sales_Office_ID AND s.Product_ID = p.Product_ID GROUP BY Sales_Office_Name; Proceedings of PLoP'94, Monticello, IL, August 1994